Custom FastAPI Software Services Development Company
Async-first FastAPI services with automatic OpenAPI documentation, Pydantic validation, and typed request/response models — ideal for ML serving, real-time backends, and microservices.
Async APIs with automatic OpenAPI docs, Pydantic validation, and typed request/response models.
Low-latency inference endpoints wrapping PyTorch, TensorFlow, and ONNX runtime.
Async WebSocket endpoints for LLM streaming, live dashboards, and collaboration backends.
Small, composable FastAPI services behind API gateways with health checks and OpenTelemetry tracing.
OAuth 2, API keys, JWT, and per-tenant rate limiting with Redis-backed quotas.
Typed clients for Stripe, OpenAI, Slack, and webhook receivers with retry and idempotency.
FastAPI emerged as the go-to Python framework for high-performance APIs precisely because it eliminates the gap between "I wrote a Python function" and "I have a production-ready, self-documented API endpoint." Pydantic validation, automatic OpenAPI schema generation, async-native request handling, and type hints as first-class citizens mean FastAPI applications are easier to test, easier to document, and faster to iterate on than any previous Python API framework. For AI and ML product teams, FastAPI is particularly compelling: it integrates naturally with Python's data science ecosystem (NumPy, Pandas, LangChain, Hugging Face) while providing the performance characteristics to serve model inference endpoints under real traffic.
Codieshub teams have used FastAPI as the API layer for machine learning inference services, healthcare interoperability layers, and multi-tenant SaaS backends since the framework hit 1.0. We've learned where FastAPI excels — async I/O-heavy workloads, inference endpoints, rapid API prototyping — and where you need additional discipline: background task management (Celery or ARQ), database connection pooling (SQLAlchemy with asyncpg), and structured logging that survives a Kubernetes pod restart.
Buyers often ask whether FastAPI can handle "enterprise" scale. The answer depends on your architecture, not the framework. Properly structured, with connection pooling, caching layers, and horizontal scaling, FastAPI services comfortably handle thousands of requests per second. Our engineers design for your actual traffic profile — not theoretical maximums — and instrument every deployment with metrics from day one so you have data to make scaling decisions rather than guesswork.
Python API projects frequently accumulate technical debt in predictable ways: validation logic scattered across endpoints, no consistent error response format, synchronous database calls blocking async routes, and missing OpenAPI documentation that every new frontend or integration partner has to reverse-engineer from source code.
Codieshub structures FastAPI services around explicit router modules, Pydantic schema contracts for every request and response, dependency-injected database sessions, and centralized exception handlers from the first commit. For AI-serving endpoints we separate inference logic from API routing so model loading, caching, and batching can be optimized independently of the HTTP layer.
Deliverables include a fully documented OpenAPI spec (importable into Postman or Stoplight), async endpoints benchmarked with Locust or k6 under expected load, comprehensive pytest test suites with async test support via httpx, and Docker images that pass security scans before they touch your container registry.
Get a senior Python engineer's estimate within 2 business days.
The Work
Archive · 2016 → 2026
Browse all 35 cases→
Healthcare
Healthcare SaaS for mPATH Health
Percensys Core Learning
Education
Learner & Admin Workflows for Percensys
Kapital Bank
Fintech
Fintech Web Platform for Kapital Bank
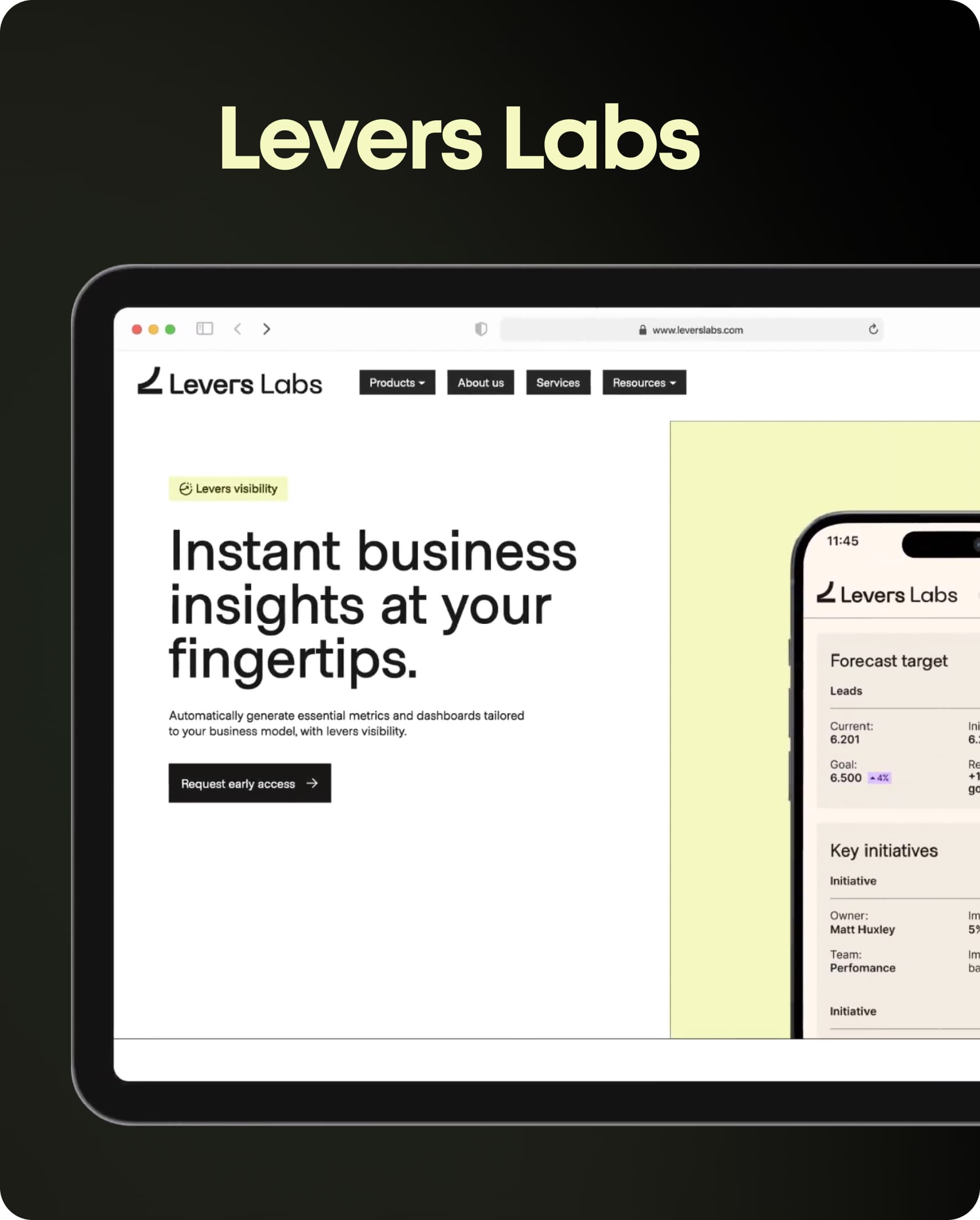
Levers Labs
Automation
AI/ML Automation Platform for Levers Labs
Investment List
Fintech
Fintech Web Platform for Investor Discovery
Dot Drive
Fintech
Fintech Web Product for Dot Drive
TeamBuilder
Healthcare
Healthcare SaaS for TeamBuilder
Eddy
Education
EdTech SaaS for Eddy
CoolBitX
Fintech
Blockchain Security Mobile App for CoolBitX
4.9 / 5
Average client rating across platforms
93%
Net Promoter Score
150%
Client retention rate
SOC 2
Type II certified
Four ways to work with us — from surgical staff augmentation to fully managed delivery. All models share the same senior-first talent bench.
Full-time engineers embedded in your team for long-running engagements.
Explore Dedicated Teams↗Add senior specialists to an existing team — vetted, onboarded, and up to speed in weeks.
Explore Staff Augmentation↗Managed fixed-scope projects with a committed timeline and deliverables.
Explore Project Delivery↗Fractional senior technical leadership for architecture, hiring, and strategy.
Explore Virtual CTO↗Why Codieshub
The shortlist we get asked about on every call — what actually separates Codieshub from a dev shop.
FastAPI's automatic OpenAPI generation means your API is documented the moment it's written. Our engineers structure routes, schemas, and error responses consistently so integration partners can onboard without a discovery call.
FastAPI is the dominant choice for serving ML model inference. Our teams build endpoints that wrap LangChain chains, Hugging Face Transformers, or custom scikit-learn models with proper input validation, response caching, and timeout handling.
Native async/await with ASGI (Uvicorn/Gunicorn) means FastAPI handles I/O-bound workloads — external API calls, database queries, file uploads — with far less thread overhead than synchronous frameworks. We tune concurrency settings for your specific request profile.
Pydantic models enforce input schemas at the boundary, not deep inside business logic. Field-level validation, custom validators, and discriminated unions mean malformed data is rejected before it touches your database or ML pipeline.
We instrument every FastAPI deployment with structured logging (structlog), Prometheus metrics via prometheus-fastapi-instrumentator, and distributed tracing (OpenTelemetry). You see latency, error rates, and throughput before you go live — not after a production incident.
OAuth2 with JWT, API key authentication, rate limiting (slowapi), CORS configuration, and dependency injection-based permission checks — our FastAPI services implement authentication and authorization consistently across every endpoint, not as per-route afterthoughts.
Reviews

Farid Huseynov
CEO · Kapital Bank
Kapital Bank case study→“Reliability and scalability are critical for us. They approached the engagement with a strong technical foundation and a clear process.”

Vito Robles
COO · Percensys
Percensys case study→“They took feedback seriously, refined the details, and made sure our content and workflows were presented in a way that really works for our learners and admins.”

Michael Ou
Founder · CoolBitX
CoolBitX case study→“Security and precision are non-negotiable for us. They demonstrated solid technical judgment, were open to feedback from our engineers, and iterated quickly.”

John Bradford
CEO · PetScreening
PetScreening case study→“An external team can be just as committed and driven as our internal one. Their dedication and attention to detail have made them invaluable.”

Oliver Dlouhy
CEO · Kiwi
Kiwi case study→“We move fast and deal with a lot of edge cases. They kept up without cutting corners, which is rare. The team stayed responsive across time zones.”

Lisa Dunbar
CEO · Paradigm Labs
Paradigm Labs case study→“They did an excellent job balancing scientific nuance with a user-friendly experience. It's clear they care about both rigor and design.”

Ryan Pamplin
CEO · Blendjet
Blendjet case study→“Managing global scale requires extreme technical precision. Codieshub re-architected our funnels to perform under massive pressure.”

Steve Gebhardt
Founder · RSVLTS
RSVLTS case study→“Our old setup crashed during every major drop until Codieshub built a beast of an engine for us. They handled our traffic spikes perfectly.”

Davis Rosser
CEO & Co-founder · Elite Amenity
Elite Amenity case study→“The digital concierge we co-built is more than tech — it's a paradigm shift in resident experience. Luxury brands can now offer faster services.”
Enterprise-grade security and compliance across every engagement.
Nearshore teams that overlap with your working hours for real-time collaboration.
Near-perfect satisfaction scores across Clutch, DesignRush, and Manifest.
Process
Our engineers are not freelancers, and we are not a marketplace. Dedicated Codieshub seniors, seated with your team.
Before kickoff
Pre-kickoff technical and strategic review.
Before a single line of code, we sit with your team to align on stack, constraints, and what success looks like. Our VP Eng, CTO, and senior leads join — not a sales engineer.
Full review of your stack, goals, and constraints before kickoff
Session led by VP Eng, CTO, and the senior leads who'll staff the work
Architecture, tooling, and team shape agreed before the first sprint
Questions
The questions we get on every intro call — answered without the marketing gloss.
A focused FastAPI backend — async endpoints, Pydantic schemas, PostgreSQL with SQLAlchemy, JWT auth, and Docker deployment — typically runs $30,000–$55,000 for a 10–14 week build with a two-engineer team. AI inference endpoints (wrapping an LLM or custom ML model) add $15,000–$25,000 depending on model serving complexity. Hourly rates for dedicated FastAPI engineers range from $65–$95/hour for senior-level work. We price after a discovery sprint so the estimate reflects your actual requirements.
Keep exploring