Hire Gemini Developer
Native text, image, audio, and video reasoning on Vertex AI. Our engineers architect RAG, agentic workflows, and multimodal pipelines wired into your Google Cloud stack.
Native text + image + audio + video reasoning for content understanding, classification, and generation.
Production deployments on Vertex AI with Model Garden, tuning jobs, and grounded generation on Google Search.
Enterprise retrieval using Vertex AI Search, vector stores, and Gemini's 1M+ token context window.
Conversational agents and vertical assistants via Vertex AI Agent Builder and Gemini function calling.
Transcript-free video analysis, scene detection, and content moderation using Gemini's video inputs.
ML-on-your-data with BigQuery ML and Gemini for SQL generation, summarization, and analytics copilots.
Google's Gemini model family — 1.5 Flash, 1.5 Pro, and the flagship 2.0 Ultra architecture — represents one of the most capable multimodal AI platforms available for enterprise integration. With native understanding of text, images, video, audio, and code in a single model call, and context windows up to 2 million tokens, Gemini opens workflows that simply weren't tractable with earlier generation models. Codieshub has been building Gemini-powered applications since the API's general availability, with production deployments across document intelligence, code generation, multimodal search, and long-context summarization.
The technical integration layer matters as much as model capability. Most enterprise Gemini projects require prompt engineering for deterministic output formats, retrieval-augmented generation to ground responses in proprietary data, function calling for tool use and API orchestration, and careful latency/cost optimization across Flash versus Pro tiers. Codieshub engineers handle this integration depth — not just API calls, but production systems with proper caching, fallback strategies, evaluation frameworks, and observability.
For companies on Google Cloud, Gemini integration through Vertex AI adds access controls, data residency guarantees, usage logging for compliance, and enterprise SLAs that the consumer API doesn't provide. Codieshub architects Gemini solutions natively on Vertex AI for enterprise clients requiring these controls, and handles the GCP IAM and VPC Service Controls configuration that makes regulated-industry deployment viable.
Companies pursuing Gemini integration face a consistent set of problems beyond basic API access: outputs that are impressive in demos but inconsistent in production, context window misuse that drives up costs without improving quality, multimodal inputs that work for simple cases but break on complex document layouts or low-quality images, and no systematic way to evaluate whether a prompt change improved or regressed model behavior across the full distribution of real inputs.
Codieshub builds Gemini integrations with an evaluation-first discipline: before any feature ships, we establish a test set of real inputs and expected output characteristics, instrument the pipeline with LLM-as-judge evaluation, and set quality and cost thresholds that govern production rollout. Prompt engineering uses structured output (JSON schema enforcement via Gemini's response_schema parameter), few-shot examples from your actual data domain, and system instruction design that reduces hallucination on domain-specific terminology. For RAG pipelines, we handle embedding, chunking strategy, vector store selection, and retrieval quality tuning.
Production Gemini deployments from Codieshub arrive with documented prompt templates version-controlled alongside application code, cost dashboards showing per-feature token consumption and projected monthly spend at current usage, and evaluation pipelines that run in CI so regressions surface before deployment. Clients gain both the immediate capability and the operational foundation to iterate on AI features without flying blind.
Tell us your use case — we'll map the architecture and cost model within 48 hours.
The Work
Archive · 2016 → 2026
Browse all 35 cases→
Healthcare
Healthcare SaaS for mPATH Health
Percensys Core Learning
Education
Learner & Admin Workflows for Percensys
Kapital Bank
Fintech
Fintech Web Platform for Kapital Bank
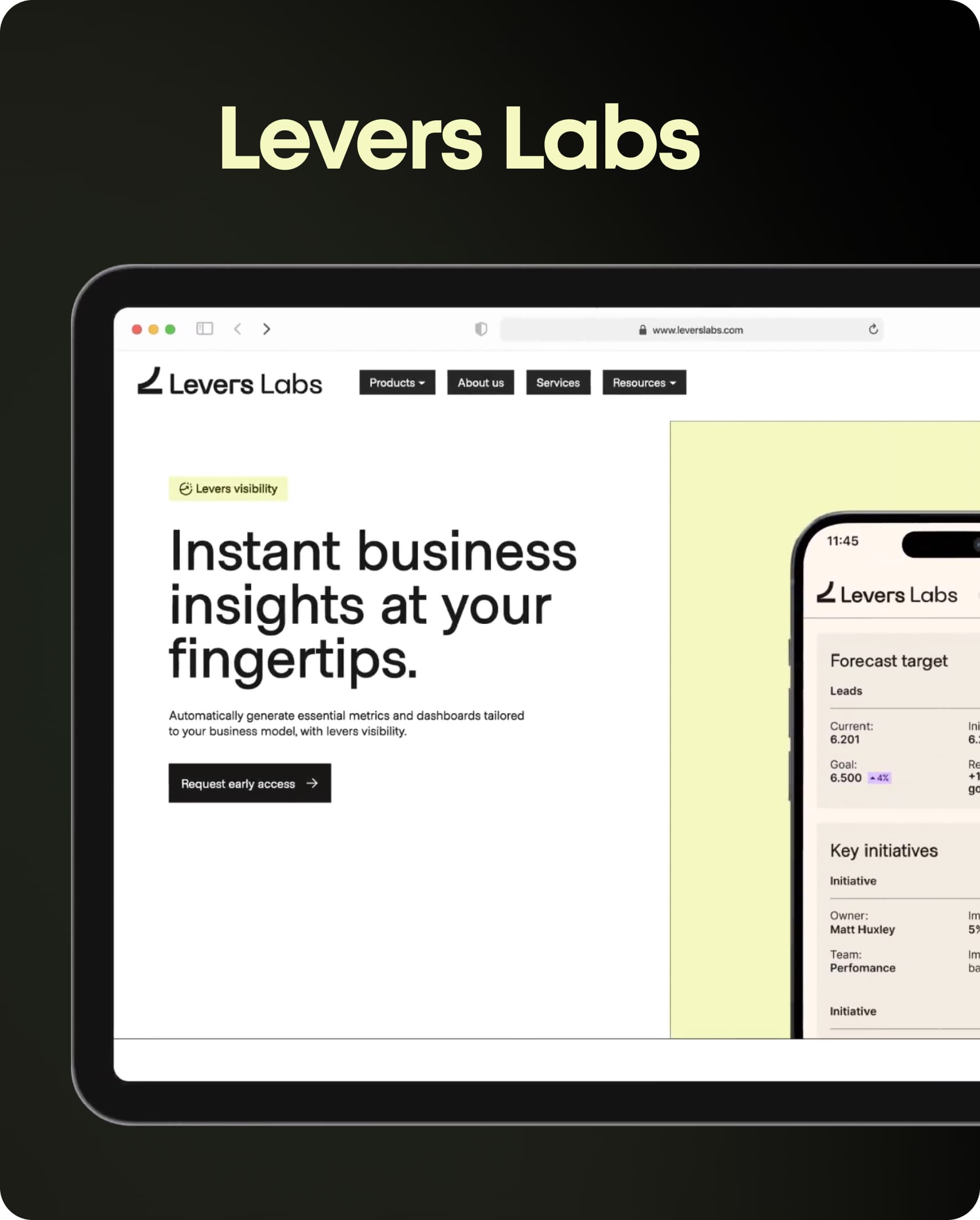
Levers Labs
Automation
AI/ML Automation Platform for Levers Labs
Rodeo
E-commerce
Shopify Subscription Plugin Built in 8 Weeks
Investment List
Fintech
Fintech Web Platform for Investor Discovery
Dot Drive
Fintech
Fintech Web Product for Dot Drive
TeamBuilder
Healthcare
Healthcare SaaS for TeamBuilder
Eddy
Education
EdTech SaaS for Eddy
4.9 / 5
Average client rating across platforms
93%
Net Promoter Score
150%
Client retention rate
SOC 2
Type II certified
Four ways to work with us — from surgical staff augmentation to fully managed delivery. All models share the same senior-first talent bench.
Full-time engineers embedded in your team for long-running engagements.
Explore Dedicated Teams↗Add senior specialists to an existing team — vetted, onboarded, and up to speed in weeks.
Explore Staff Augmentation↗Managed fixed-scope projects with a committed timeline and deliverables.
Explore Project Delivery↗Fractional senior technical leadership for architecture, hiring, and strategy.
Explore Virtual CTO↗Why Codieshub
The shortlist we get asked about on every call — what actually separates Codieshub from a dev shop.
Gemini natively processes images, PDFs, video frames, and audio alongside text in a single API call. We build pipelines that ingest complex document types — scanned forms, mixed-media reports, technical drawings — and extract structured data without per-modality preprocessing pipelines.
With 1.5 Pro's 1M-token context window, entire codebases, lengthy contracts, or multi-year document archives fit in a single prompt. We architect long-context workflows that balance context utilization against per-call cost, using caching for shared context across requests.
Gemini's function calling enables reliable API orchestration — the model decides which tools to invoke, we handle the execution and response injection. We build multi-step agentic workflows that can query databases, call internal APIs, and chain results without deterministic scripting.
Gemini's response_schema parameter enforces JSON structure at the API level, eliminating regex parsing and output validation layers. We design schemas that capture exactly the data your downstream systems need, with constrained value sets where appropriate.
Every Gemini feature we build ships with an evaluation suite — LLM-as-judge pipelines, human preference datasets, and regression baselines. You know quantitatively whether a model update or prompt change improved your product before users see it.
Enterprise clients get Gemini through Vertex AI with data residency controls, VPC Service Controls for network isolation, Cloud Audit Logs for all model calls, and customer-managed encryption — the governance layer regulated industries require.
Reviews

Farid Huseynov
CEO · Kapital Bank
Kapital Bank case study→“Reliability and scalability are critical for us. They approached the engagement with a strong technical foundation and a clear process.”

Vito Robles
COO · Percensys
Percensys case study→“They took feedback seriously, refined the details, and made sure our content and workflows were presented in a way that really works for our learners and admins.”

Ryan Pamplin
CEO · Blendjet
Blendjet case study→“Managing global scale requires extreme technical precision. Codieshub re-architected our funnels to perform under massive pressure.”

Steve Gebhardt
Founder · RSVLTS
RSVLTS case study→“Our old setup crashed during every major drop until Codieshub built a beast of an engine for us. They handled our traffic spikes perfectly.”

Michael Ou
Founder · CoolBitX
CoolBitX case study→“Security and precision are non-negotiable for us. They demonstrated solid technical judgment, were open to feedback from our engineers, and iterated quickly.”

John Bradford
CEO · PetScreening
PetScreening case study→“An external team can be just as committed and driven as our internal one. Their dedication and attention to detail have made them invaluable.”

Oliver Dlouhy
CEO · Kiwi
Kiwi case study→“We move fast and deal with a lot of edge cases. They kept up without cutting corners, which is rare. The team stayed responsive across time zones.”

Lisa Dunbar
CEO · Paradigm Labs
Paradigm Labs case study→“They did an excellent job balancing scientific nuance with a user-friendly experience. It's clear they care about both rigor and design.”

Davis Rosser
CEO & Co-founder · Elite Amenity
Elite Amenity case study→“The digital concierge we co-built is more than tech — it's a paradigm shift in resident experience. Luxury brands can now offer faster services.”
Enterprise-grade security and compliance across every engagement.
Nearshore teams that overlap with your working hours for real-time collaboration.
Near-perfect satisfaction scores across Clutch, DesignRush, and Manifest.
Process
Our engineers are not freelancers, and we are not a marketplace. Dedicated Codieshub seniors, seated with your team.
Before kickoff
Pre-kickoff technical and strategic review.
Before a single line of code, we sit with your team to align on stack, constraints, and what success looks like. Our VP Eng, CTO, and senior leads join — not a sales engineer.
Full review of your stack, goals, and constraints before kickoff
Session led by VP Eng, CTO, and the senior leads who'll staff the work
Architecture, tooling, and team shape agreed before the first sprint
Questions
The questions we get on every intro call — answered without the marketing gloss.
Gemini 1.5 Flash is 10–15x cheaper per token than 1.5 Pro and handles the majority of enterprise use cases well: classification, extraction, summarization of well-structured documents, simple Q&A, and code generation for common patterns. Gemini 1.5 Pro earns its cost premium for complex reasoning chains, ambiguous document interpretation, tasks requiring nuanced instruction following, and long-context analysis of unstructured content where Flash degrades. Our standard architecture uses Flash as the default and routes to Pro based on a lightweight complexity classifier, keeping costs predictable while maintaining quality for hard cases. Typical blended cost for a document processing pipeline runs $0.50–$2.00 per 1,000 documents depending on length and routing ratio.
Keep exploring